感觉同源策略还挺难的,23333……
URL和URI的区别:
参考文章:https://www.cnblogs.com/chengdabelief/p/6635045.html
1 | 理解URI和URL的区别,我们引入URN这个概念。 |
三者的关系如下:
换句话说:1
2
3URI分为三种,URL or URN or (URL and URI)
URL代表资源的路径地址,而URI代表资源的名称。
通过URL找到资源的网络位置进行标识,如:1
2
3http://example.org/absolute/URI/with/absolute/path/to/resource.txt
ftp://example.org/resource.txt
通过URI找到资源是通过对名称进行标识,这个名称在某命名空间中,并不代表网络地址,如:1
urn:issn:1535-3612
同源策略
什么是同源策略?
话说在前面,同源策略是一个模型,并非一个标准,毕竟一个标准在不同的情况下的实现可能是千变万化的。
web应用的安全模型中是一个重要概念。在这个策略下,web浏览器允许第一个页面的脚本访问第二个页面里的数据,但是也只有在两个页面有相同的源时。源是由URI,主机名,端口号组合而成的。这个策略可以阻止一个页面上的恶意脚本通过页面的DOM对象获得访问另一个页面上敏感信息的权限。
对于普遍依赖于cookie维护授权用户session的现代浏览器来说,这种机制有特殊意义。客户端必须在不同站点提供的内容之间维持一个严格限制,以防丢失数据机密或者完整性。
既为同源,何时同源?
RFC6454中有定义URI源的算法定义。对于绝对的URIs,源就是{协议,主机,端口}定义的。只有这些值完全一样才认为两个资源是同源的。
只要三个元素中有一个不符合,便称为跨域。
为了举例,下面的表格给出了与URL “http://www.example.com/dir/page.html" 的对比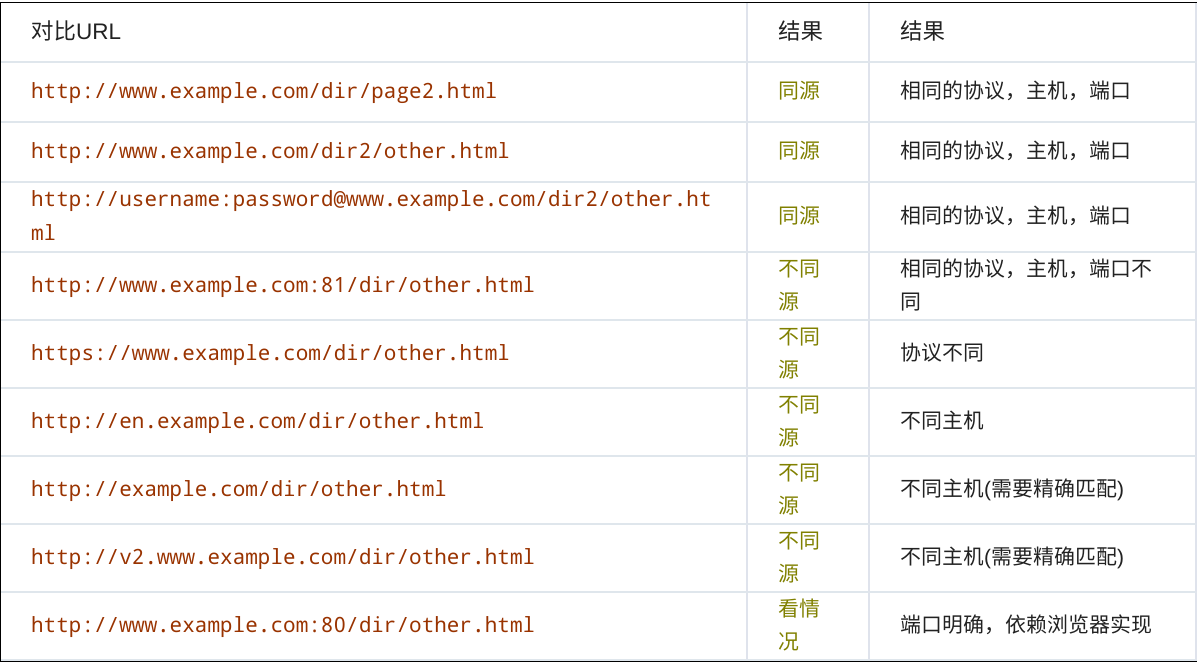
由此可见,只要且必须满足{协议,主机,端口}一致的两个值就是同源的。
安全考量
现在记住一句话1
2这个策略可以阻止一个页面上的恶意脚本通过页面的DOM对象获得访问另一个页面上敏感信息的权限。
客户端必须在不同站点提供的内容之间维持一个严格限制,以防丢失数据机密或者完整性。
然后来看一个例子,关于同源策略所能预防的问题
假设用户在访问银行网站,并且没有登出。然后他又去了任意的其他网站,刚好这个网站有恶意的js代码,在后台请求银行网站的信息。因为用户目前仍然是银行站点的登陆状态,那么恶意代码就可以在银行站点做任意事情。例如,获取你的最近交易记录,创建一个新的交易等等。因为浏览器可以发送接收银行站点的session cookies,在银行站点域上。访问恶意站点的用户希望他访问的站点没有权限访问银行站点的cookie。当然确实是这样的,js不能直接获取银行站点的session cookie,但是他仍然可以向银行站点发送接收附带银行站点session cookie的请求,本质上就像一个正常用户访问银行站点一样。关于发送的新交易,甚至银行站点的CSRF(跨站请求伪造)防护都无能无力,因为脚本可以轻易的实现正常用户一样的行为。所以如果你需要session或者需要登陆时,所有网站都面临这个问题。
如果未有同源策略,那么非同源的网站,也就是某些非正规的网站中的恶意代码可能对我们的银行网站进行访问,甚至进行一些操作,如果有同源策略进行防护的话,那么在同源网站和非同源网站便会存在一道墙,非同源网站的恶意代码想要进入就困难了,对于同源的站点就如有一条通道一样。
简而言之:浏览器的同源策略,限制了来自不同源的”document”或脚本,对当前“document”读取或设置某些属性。